Sekarang, dampak dari peluncuran R1 dengan cepat menyebar ke seluruh AS karena industri teknologi mencoba memahami bagaimana DeepSeek melakukan hal tersebut dan apakah perusahaan rintisan ini melakukannya semurah yang diklaimnya. Sudah ada kecurigaan bahwa perusahaan rintisan asal Tiongkok ini membangun chatbot-nya dengan memanfaatkan teknologi barat, menghindari biaya yang sangat besar untuk mengembangkan model bahasa yang besar.
Di San Francisco, para eksekutif dan karyawan AI segera mengurai teknologi DeepSeek. Beberapa staf OpenAI mencoba mencari tahu bagaimana DeepSeek dapat merilis model seperti itu, menurut orang-orang yang mengetahui masalah ini yang berbicara tanpa menyebut nama untuk mendiskusikan masalah pribadi.
Orang itu mengatakan bahwa ada perasaan di perusahaan bahwa OpenAI perlu menanggapi perkembangan dari perusahaan-perusahaan China dengan sangat serius, karena ini merupakan kesempatan untuk berinovasi dan meningkatkan model yang sudah ada. Chief Executive Officer OpenAI Sam Altman baru-baru ini mengatakan kepada para karyawannya bahwa rilis ini menandai perubahan lanskap besar bagi startup tersebut, kata salah satu orang.
“R1 DeepSeek adalah model yang mengesankan,” Altman memposting dalam reaksi publik pertamanya di X. ”Kami jelas akan memberikan model yang jauh lebih baik dan juga menyegarkan untuk memiliki pesaing baru!”
deepseek's r1 is an impressive model, particularly around what they're able to deliver for the price.
— Sam Altman (@sama) January 28, 2025
we will obviously deliver much better models and also it's legit invigorating to have a new competitor! we will pull up some releases.
Meta Platforms Inc, yang juga berfokus pada model AI open-source, telah membentuk tim internal yang berfokus pada analisis DeepSeek untuk lebih memahami bagaimana DeepSeek dibuat dan apa yang dapat dilakukannya, menurut orang-orang yang mengetahui hal tersebut. Perusahaan telah membentuk gugus tugas serupa untuk menilai pesaing utama lainnya, seperti model GPT-4 dari OpenAI dan Gemini dari Google, kata orang-orang tersebut.
Hampir dalam semalam, DeepSeek telah menjungkirbalikkan banyak asumsi di dalam Silicon Valley tentang keekonomisan membangun AI, serta metode teknis terbaik untuk mengembangkan teknologi dan sejauh mana keunggulan AS atas para pesaingnya di Tiongkok. Selama lebih dari dua tahun terakhir sejak ChatGPT memulai hiruk-pikuk AI global, industri ini bertaruh bahwa jalan menuju AI yang lebih baik sangat bergantung pada pengeluaran yang besar untuk chip yang lebih canggih dari perusahaan-perusahaan seperti Nvidia Corp. dan pusat data yang semakin masif untuk menampungnya.
Presiden AS Donald Trump menyambut baik perkembangan ini sebagai “hal yang baik, karena Anda tidak perlu mengeluarkan banyak uang.” Pemimpin industri Nvidia, yang sahamnya terpukul oleh debut DeepSeek, juga memujinya sebagai “kemajuan AI yang luar biasa” dalam sebuah pernyataan pada hari Senin.
“Perilisan DeepSeek AI dari perusahaan Tiongkok seharusnya menjadi peringatan bagi industri kita bahwa kita harus fokus untuk bersaing agar bisa menang,” tambah Trump.
Kejatuhan pasar saham sangat mengejutkan. Hype atas prestasi DeepSeek menyebabkan kerugian hampir US$1 triliun pada saham teknologi AS dan Eropa pada hari Senin karena para investor mempertanyakan rencana pengeluaran beberapa perusahaan terbesar di Amerika. Penurunan saham di perusahaan pembuat chip AI Nvidia saja menghapus sekitar US$589 miliar nilai pasar, yang merupakan penurunan terbesar dalam sejarah pasar saham AS.
Sementara itu, di Washington DC, para anggota parlemen masih harus mencari cara terbaik untuk mengalahkan kemajuan China dalam teknologi yang dianggap penting bagi militer dan ekonominya, mengingat pembatasan ekspor chip yang dilakukan oleh pemerintahan Biden tidak cukup. David Sacks, kepala kripto dan AI Presiden Donald Trump, mengatakan bahwa DeepSeek menunjukkan bahwa perlombaan AI global akan sangat kompetitif - sembari menyalahkan pemerintahan Biden atas regulasi yang “melumpuhkan” pengembangan AI.
Lebih memperumit masalah, ketidakpastian baru atas investasi AI yang besar muncul hanya beberapa hari setelah Trump memperjuangkan usaha patungan senilai US$100 miliar dari OpenAI, SoftBank Group Corp. dan Oracle Corp. untuk meningkatkan daya saing AS dengan berinvestasi di pusat data dan infrastruktur fisik lainnya. Sekarang, ada pertanyaan baru tentang alasan untuk anggaran AI stratosfer.
“Ini adalah pergeseran paradigma,” kata Ali Ghodsi, CEO Databricks Inc. “Model-model yang dapat bernalar ini jauh lebih murah untuk diproduksi sehingga Anda akan melihatnya didemokratisasi. Anda akan melihat inovasi dari berbagai penjuru dunia yang tak terduga.”
Kebangkitan DeepSeek
Bagi Liang Wenfeng, DeepSeek dimulai sebagai proyek sampingan. Liang, 40 tahun, menciptakan DeepSeek pada tahun 2023 sebagai cabang dari divisi AI untuk hedge fund miliknya, Zhejiang High-Flyer Asset Management.
Liang mampu memanfaatkan beberapa talenta lokal dan, yang terpenting, chip. Dia telah mulai menimbun sekitar 10.000 GPU Nvidia A100 - versi lama dari teknologi utama untuk melatih sistem AI - sebelum AS memberlakukan pembatasan ekspor. Dan sebagian besar peneliti terbaiknya adalah lulusan baru dari universitas-universitas ternama di Tiongkok, katanya, menekankan perlunya Tiongkok mengembangkan ekosistem domestiknya sendiri.
DeepSeek dengan cepat merilis sejumlah model AI sumber terbuka, dimulai dengan DeepSeek LLM pada akhir 2023. Dua model yang lebih canggih - V2 dan V3 - keluar pada pertengahan dan akhir 2024. Namun, model R1 DeepSeek, yang dirilis pada pertengahan Januari, yang benar-benar menarik perhatian.
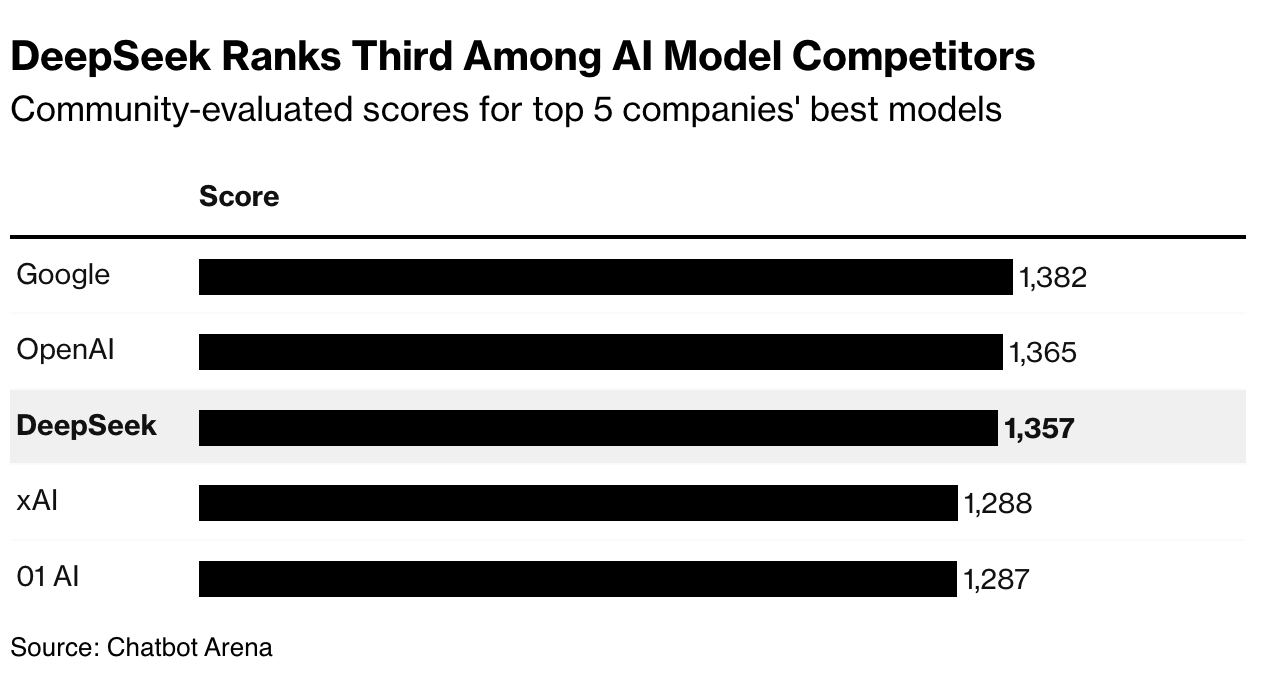
Seperti beberapa model terbaru dari OpenAI, Google, dan Anthropic, R1 dimaksudkan untuk meniru cara manusia merenungkan masalah dengan menghabiskan waktu untuk menghitung jawaban sebelum merespons pertanyaan pengguna. Namun, versi DeepSeek berbeda dalam hal efisiensi.
Tim di belakangnya menghasilkan beberapa inovasi sederhana namun penting, seperti menemukan cara untuk memanfaatkan lebih banyak chip komputer yang mereka miliki. Terobosan lain: bersandar pada teknik yang dikenal sebagai pembelajaran penguatan yang memberi penghargaan pada sistem untuk jawaban yang benar dan menghukumnya untuk jawaban yang salah.
Aplikasi DeepSeek terbukti populer di kalangan pengguna AS, sebagian berkat chatbot yang ramah dan terdengar agak canggung yang menunjukkan dengan sangat rinci bagaimana ia berencana untuk menanggapi pertanyaan seseorang sebelum menyelami hasilnya. Pendekatan ini mencakup lebih banyak detail daripada, katakanlah, model penalaran terbaru OpenAI. Dan tidak seperti OpenAI, yang mengenakan biaya sebanyak $200 per bulan untuk akses tak terbatas ke model penalarannya yang paling canggih, di antara fitur-fitur lainnya, DeepSeek saat ini menawarkan layanannya secara gratis.
Tetapi DeepSeek juga menyensor topik-topik yang sensitif di Cina. Menanyakan tentang Revolusi Kebudayaan Cina, misalnya, mungkin akan memancing tanggapan: “Maaf, itu di luar cakupan saya saat ini. Mari kita bicarakan hal lain saja.”
Dalam waktu satu jam setelah peluncuran R1, Ghodsi mengatakan bahwa ia menerima permintaan pertamanya dari pelanggan DataBricks yang menanyakan tentang penggunaannya. Permintaan semakin meningkat sejak saat itu. Secara khusus, katanya, perusahaan ingin mengetahui cara menambahkan kemampuan seperti penalaran dari DeepSeek di atas model AI Databricks yang sudah ada - sesuatu yang ditunjukkan oleh upaya DeepSeek yang bisa dilakukan dengan biaya murah, katanya.
“Kecepatan dan tingkat ketertarikan ini belum pernah terjadi sebelumnya bagi kami,” ujar Ghodsi.
Mehdi Osman, CEO perusahaan perangkat lunak OpenReplay, mengatakan bahwa perusahaannya secara tradisional menggunakan layanan dari OpenAI, Anthropic, dan Mistral, dan bahwa kemampuan penalaran DeepSeek tampaknya setara dengan OpenAI.
“Jika OpenAI tidak menurunkan harga mereka, saya pikir banyak pengembang akan beralih ke DeepSeek dalam beberapa bulan mendatang,” kata Osman.
OpenAI menolak berkomentar. DeepSeek tidak menanggapi permintaan komentar.
“Ini seperti keluar dari jalur,” kata Demis Hassabis, CEO Google DeepMind, kepada Bloomberg News pekan lalu di Davos. “Tidak diragukan lagi, ini adalah sistem yang mengesankan.”
Namun seperti orang lain di industri ini, Hassabis menyatakan ketidakpastian tentang bagaimana model DeepSeek bekerja, termasuk sejauh mana ia bergantung pada model-model Barat lainnya.
Sementara itu, Altman mengatakan kepada karyawan OpenAI bahwa perusahaan rintisannya sedang mencoba memahami apakah dan sejauh mana kinerja DeepSeek merupakan hasil dari penyulingan model OpenAI - yaitu, menggunakan output dari AI perusahaan tersebut untuk melatih model yang berbeda agar memiliki kemampuan yang sama - atau merupakan terobosan penelitian independen, menurut seseorang yang mengetahui hal tersebut.
“Bahkan jika itu [menyaring model OpenAI] menghemat sedikit waktu dan sedikit uang - yang tidak saya katakan mereka lakukan - jelas ada banyak pekerjaan teknis asli di sini yang terjadi di koran yang dapat dilihat dan dinilai oleh orang-orang,” kata Miles Brundage, seorang peneliti kebijakan AI independen yang baru-baru ini meninggalkan OpenAI.
Beberapa pendiri teknologi dan pemodal ventura di AS juga skeptis dengan harga yang sebenarnya untuk teknologi DeepSeek. Banyak orang, termasuk Brundage, mempertanyakan apakah estimasi pelatihan DeepSeek sebesar US$5,6 juta sudah termasuk biaya eksperimen penelitian sebelumnya serta biaya tetap untuk investasi dalam unit pemrosesan grafis, seperti membangun pusat data.
Liang, pada bagiannya, menyatakan bahwa biaya dan penggalangan dana bukanlah perhatian utamanya. Sebaliknya, hambatan untuk kemajuan lebih lanjut, Liang mengatakan dalam sebuah wawancara dengan outlet China 36kr, adalah pembatasan AS pada akses ke chip terbaik.
“Lebih banyak investasi tidak selalu menghasilkan lebih banyak inovasi,” kata Liang. “Jika tidak, perusahaan-perusahaan besar akan mengambil alih semua inovasi.”
Lanskap kompetitif yang baru
Dalam minggu-minggu menjelang hiruk-pikuk DeepSeek, beberapa perusahaan besar yang mungkin telah disinggung Liang telah melenturkan otot-otot keuangan mereka lebih banyak lagi.
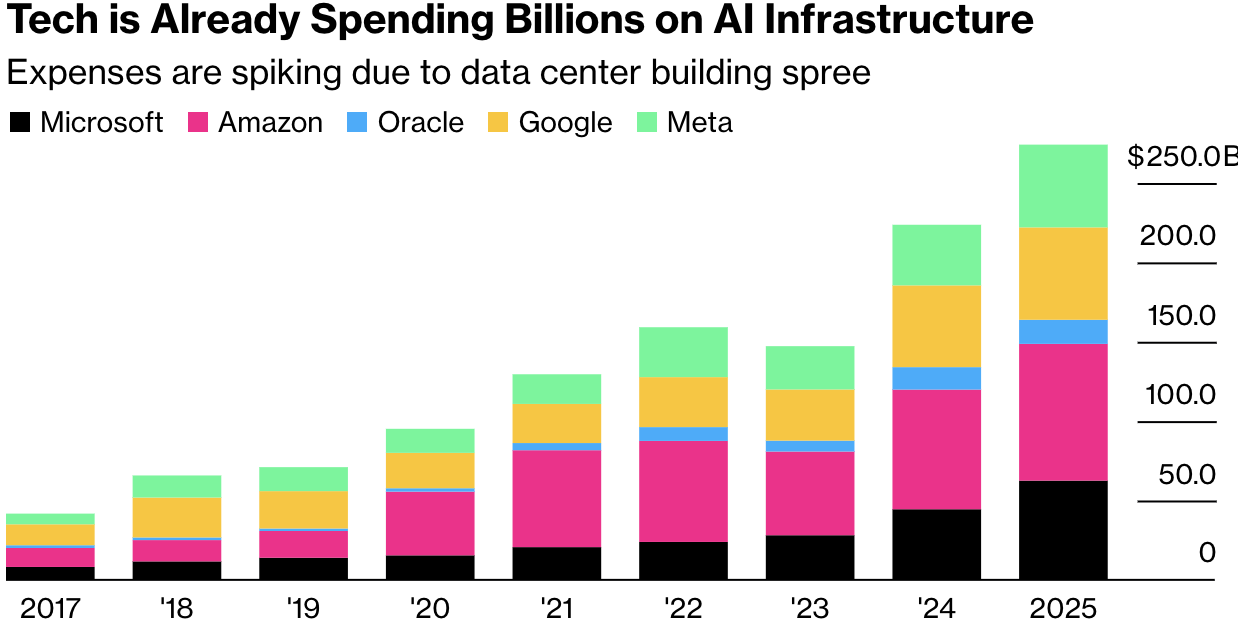
Amazon memproyeksikan belanja modal sekitar US$75 miliar pada tahun 2024, dan jumlah yang meningkat tahun ini, sebagian besar untuk infrastruktur teknologi seperti chip dan pusat data yang mendukung kecerdasan buatan. Meta mengatakan akan menginvestasikan sebanyak US$65 miliar untuk proyek-proyek yang berhubungan dengan AI pada tahun 2025. Dan Microsoft mengatakan akan menghabiskan US$80 miliar untuk pusat data AI pada tahun fiskal ini.
Sebagian besar pengeluaran perusahaan komputasi awan terbesar digunakan untuk unit pemrosesan grafis Nvidia. Amazon, Google, dan Microsoft juga membangun chip khusus yang dirancang untuk AI, pekerjaan yang mungkin kurang berguna dalam jangka panjang jika pengembang dapat membangun dan menjalankan model pada perangkat keras yang tidak terlalu terspesialisasi, Stefan Slowinski, seorang analis dari BNP Paribas Exane, menulis dalam sebuah catatan penelitian pada hari Senin.
Raksasa cloud sudah bergulat dengan pertanyaan dari investor tentang pengembalian dari pengeluaran AI mereka yang cukup besar. Microsoft, misalnya, telah berjuang untuk memonetisasi chatbots Copilot yang telah dipanggang ke dalam sebagian besar lini produknya. Sementara itu, Amazon telah mengikuti saingan utamanya dalam mengembangkan model bahasanya sendiri yang besar, bahkan ketika mereka menanamkan chatbots dan alat AI lainnya ke dalam bisnis ritel dan komputasi awan.
Namun, investasi besar kedua perusahaan ini mungkin akan terbayar di kemudian hari. Amazon bertaruh bahwa statusnya sebagai penyedia daya komputasi sewaan terbesar akan membantunya meraih kesuksesan saat perusahaan lain melatih dan menjalankan program AI di server Amazon Web Services. Microsoft lebih fokus membangun pusat data yang menjalankan model AI daripada melatihnya, menurut Mark Moerdler, seorang analis di Bernstein Societe Generale Group, yang memperkirakan pengeluaran perusahaan akan melambat pada awal tahun depan. “Kami yakin mereka lebih banyak membangun kapasitas untuk menyimpulkan dan bukannya melatih,” katanya. “Jika hal itu benar, saya rasa DeepSeek tidak akan menjadi masalah bagi Microsoft.”
Pertanyaan besarnya adalah apakah perusahaan teknologi besar AS akan mengadopsi aspek-aspek pendekatan DeepSeek. Beberapa pengembang AI mengatakan bahwa kesuksesan perusahaan rintisan asal Tiongkok ini dapat mempercepat langkah menuju AI yang lebih murah dan lebih menguntungkan - menggerakkan perkembangan alami yang telah mendorong hampir semua perkembangan teknologi besar, mulai dari chip hingga smartphone.
“Masa depan LLM adalah milik mereka yang fokus pada teknik yang lebih efisien, bukan pada komputasi yang lebih banyak,” ujar Aidan Gomez, CEO perusahaan rintisan AI Cohere. “Kami sudah meyakini hal ini sejak lama, namun akhirnya hal ini menjadi kenyataan di seluruh industri.”
Dengan bantuan dari Dina Bass, Matt Day, Mark Bergen, Yazhou Sun, Jason Kao, Kurt Wagner, Dana Wollman, dan Julaiza Alvarez
(bbn)